
AI checker accuracy statistics for 2026 show a shift to probabilistic modeling, where detection assigns likelihood scores based on text patterns. In controlled testing, GPT-4o output reached 99.58% AI likelihood, with 100% sensitivity and 99.6% specificity at a defined threshold. Real-world performance drops. A separate study reported a 12% overall error rate, including 14% false positives on human-written work and 5% false negatives on AI-generated text. These systems function as indicators that require review, not as evidence for final decisions.
This research looks at the numbers to understand how well AI detection tools can tell the difference between human and AI-written text. It also shows where they make mistakes and where the numbers are less reliable, especially as the text is edited or written in a more natural way.


2026 AI Detection Accuracy: Raw AI vs Edited Text
The results below, taken together, show how detection performs across different conditions, detection tools, and text types.
- Independent performance estimates cluster between 85% and 90% in external evaluations, while some tools report 83%–93% or even 98%, though those higher figures come from vendor claims rather than controlled studies.
- In academic testing, GPT-4o output reached 99.58% AI likelihood with GPTZero, 94.35% with ZeroGPT, and 93.56% with Corrector.
- False positive rates remain substantial: 15.6% (GPTZero), 45.8% (Winston), 9.8% (ZeroGPT), and 17.6% (Originality.ai) in one controlled dataset.
- Human-written academic texts were flagged as AI at notable rates, including 30.4% under Corrector and 16% under ZeroGPT.
- Tool disagreement is measurable. The same human dataset produced average AI scores of 5.88% (GPTZero), 27.55% (ZeroGPT), and 36.90% (Corrector).
- Domain-specific writing introduces instability. Structured academic prose tends to resemble AI patterns, which increases misclassification risk.
- Editing weakens calibration. In one experiment, modifying AI output reduced detection scores by 21%, even when the underlying content remained similar.
If you need to submit a paper for one of your law classes, contact our law essay writing service and be sure to submit 100% human-generated content every time.
Accuracy Drop in "Humanized" Text
Raw AI output follows predictable statistical patterns that detectors recognize with high consistency. That explains why scores approach the upper limit in controlled conditions.
That changes once humans intervene. In a classroom experiment, students edited AI-generated responses to mask their origin.
AI-Generated Text
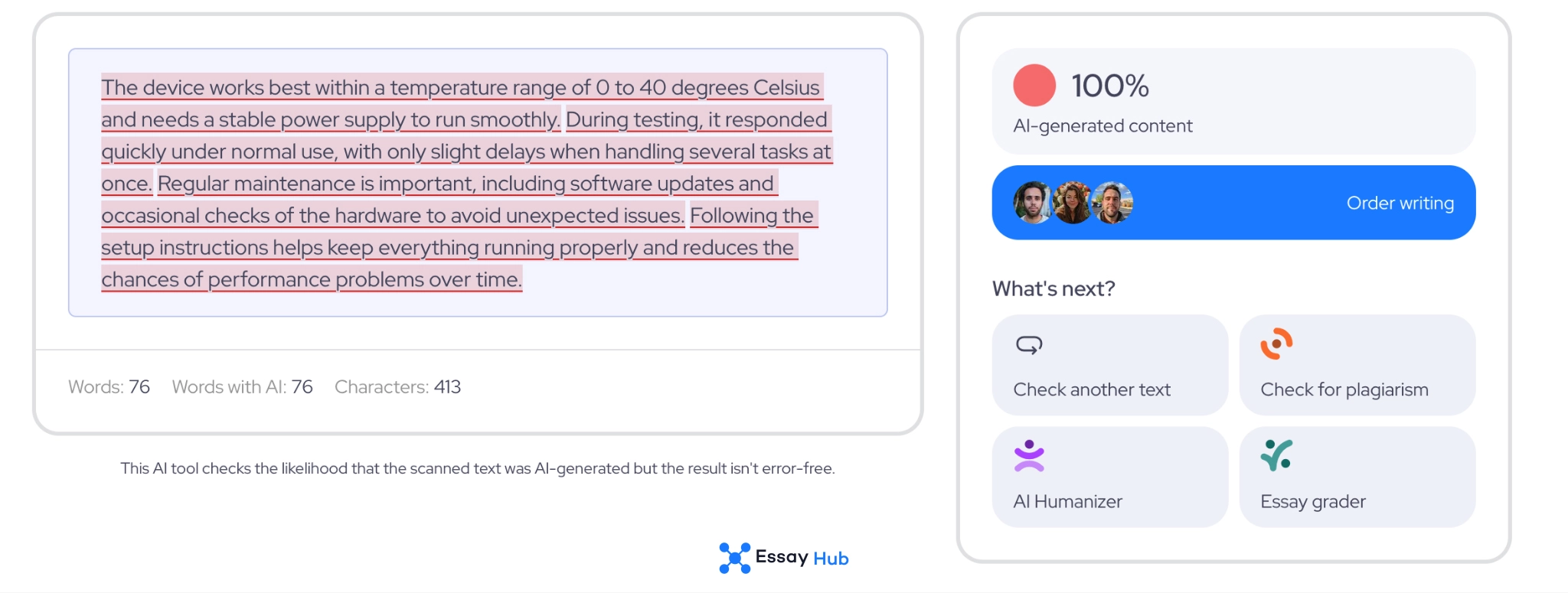
Humanized Text
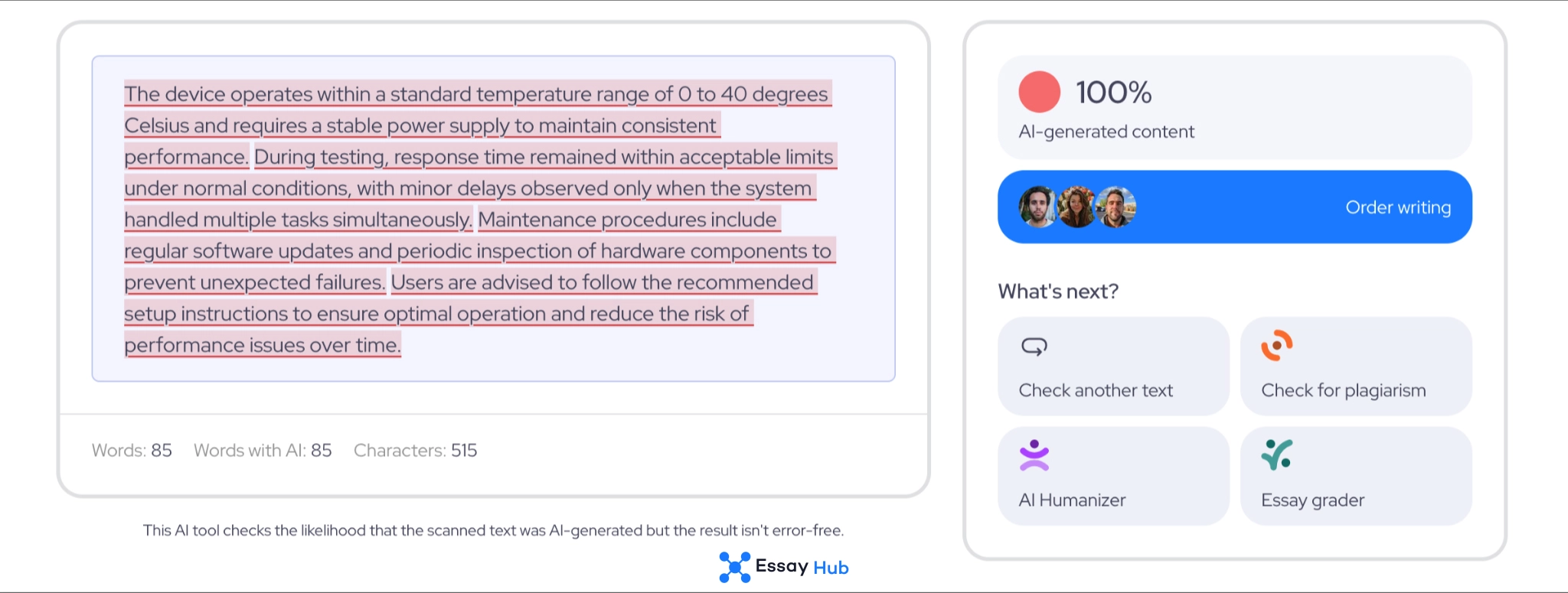
As a result:
- Average AI scores dropped by 21%
- Recall decreased by 20.6%
- Accuracy decreased by 9.1%
- Precision decreased by 3.7%
- F1 scores decreased by 12.6%
ZeroGPT’s F1 moved from 0.91 on raw AI text to 0.74 after editing. GPTZero fell from 0.88 to 0.81.
These changes did not come from superficial edits. Successful cases required substantial rewriting, which reduced similarity to the original AI output.
This pattern explains why detection feels reliable in controlled tests yet unstable in practice. Once text becomes hybrid, shaped by both AI and human revision, the statistical signals become less clear. The system still produces a score, but that score is less certain.
False Positives in AI Detection Tools
A false positive is a Type I error, which means a system labels human-written content as AI-generated. In plain terms, this is a false accusation. In academic settings, that label can trigger serious consequences, including misconduct claims and grade penalties. Repeated false positives can also lead to what many now call AI shaming, where students are labeled as dishonest based on a probability score rather than verified evidence. That is why AI checkers false positive rates matter more than headline accuracy numbers.
Independent research shows that false positives are not theoretical. In one large classroom study, around 14% of students were flagged as using AI when they had not. That figure sets a practical baseline. It shows that real-world error can sit well above what tools advertise.
Originality.ai
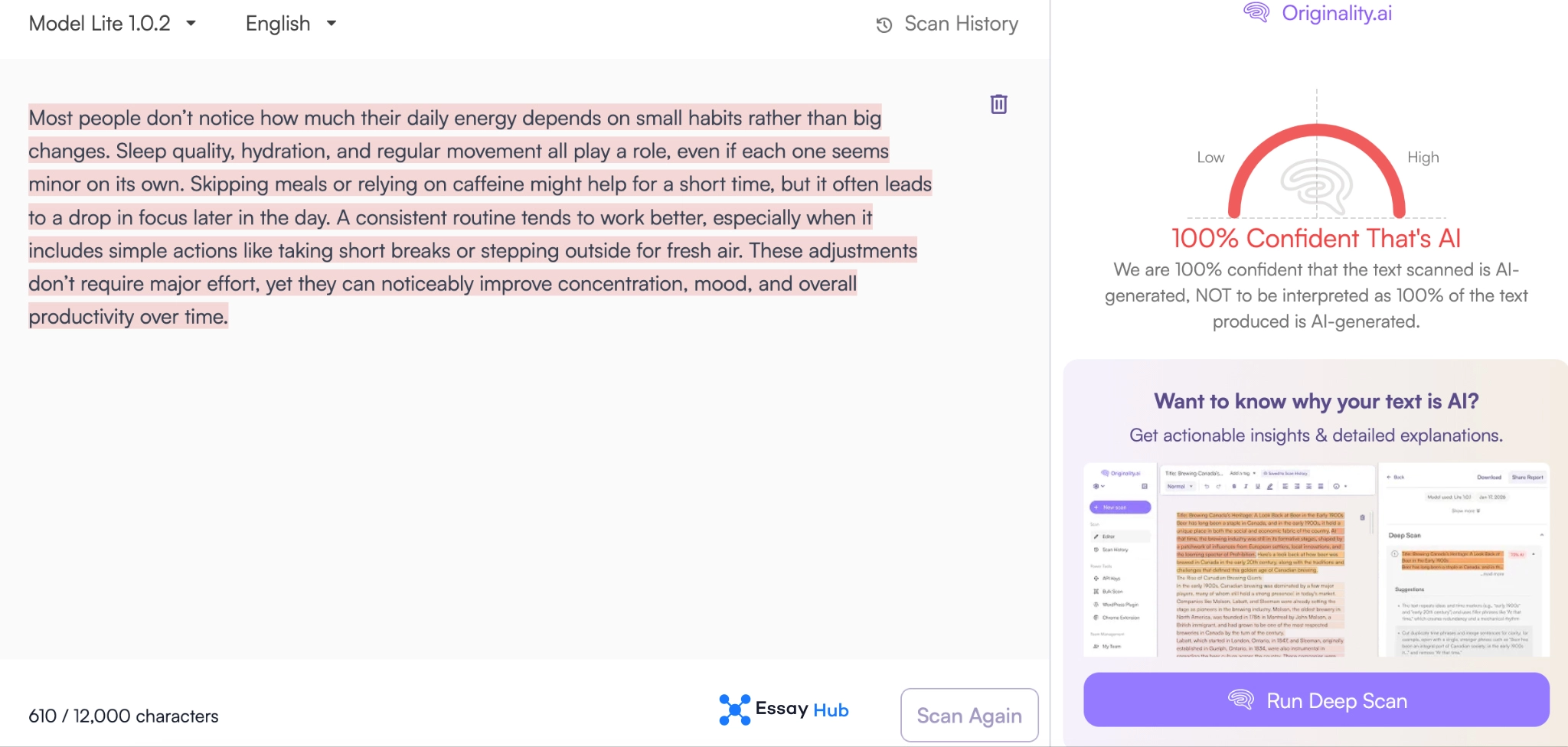
Originality.ai reports a false positive rate between 0.5% and 1.5%, depending on the detection mode. Independent testing places that number slightly higher, around 1.5% to 2%. The difference is not extreme, but it is consistent. Even at 2%, the tool would incorrectly flag 1 human written text out of every 50. In high-volume academic environments, that translates into a steady stream of incorrect accusations. The system performs within a narrow range, but it still operates on probability rather than certainty.
Turnitin
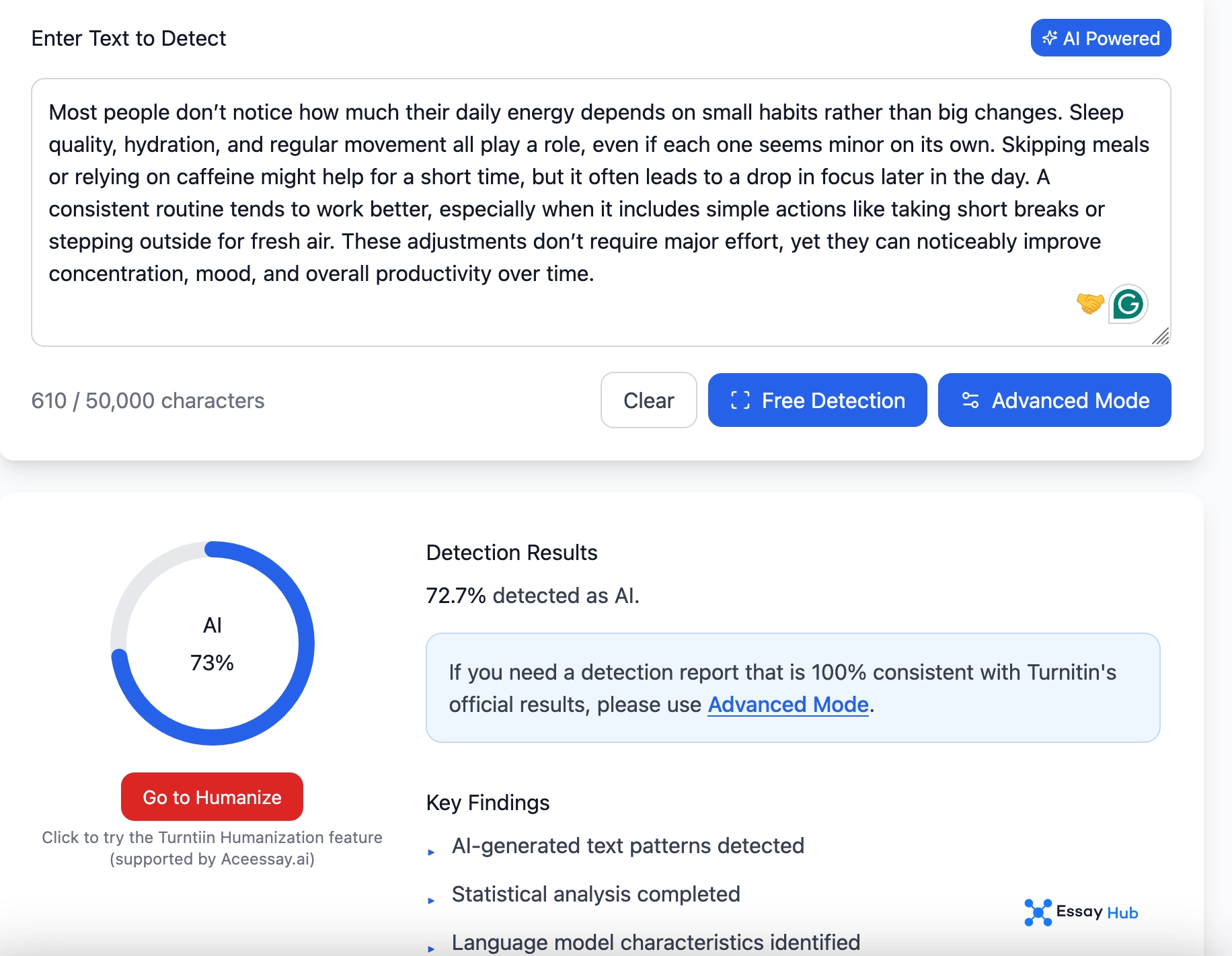
Turnitin claims a false positive rate of less than 1%. That figure is often cited in discussions of Turnitin AI detection accuracy. However, there is no matching independent dataset in the provided research that confirms or challenges this number directly. This creates a blind spot. Without external validation, the claim cannot be placed on the same footing as measured results from controlled studies. The absence of independent verification matters as much as the number itself.
EssayHub AI Detector
EssayHub AI detector reports a false positive rate above 1%, with measured results between 1% and 1.5%. The difference is small, which suggests relatively stable calibration. Still, this means about 1 to 1.5 out of every 100 human-written texts may be flagged incorrectly. In large datasets, these errors add up, making false positives a consistent outcome rather than a rare exception.
GPTZero
GPTZero reports a false positive rate of less than 1%. Independent testing shows a higher figure, around 3.3%. The gap is small in absolute terms, yet meaningful in practice. At 3.3%, roughly 1 in 30 human-written texts could be flagged incorrectly. In one academic study, GPTZero also flagged a measurable portion of student writing despite it being verified as original. This reinforces a consistent pattern. Performance remains strong in controlled scenarios, but error increases when applied to real writing samples.
Winston
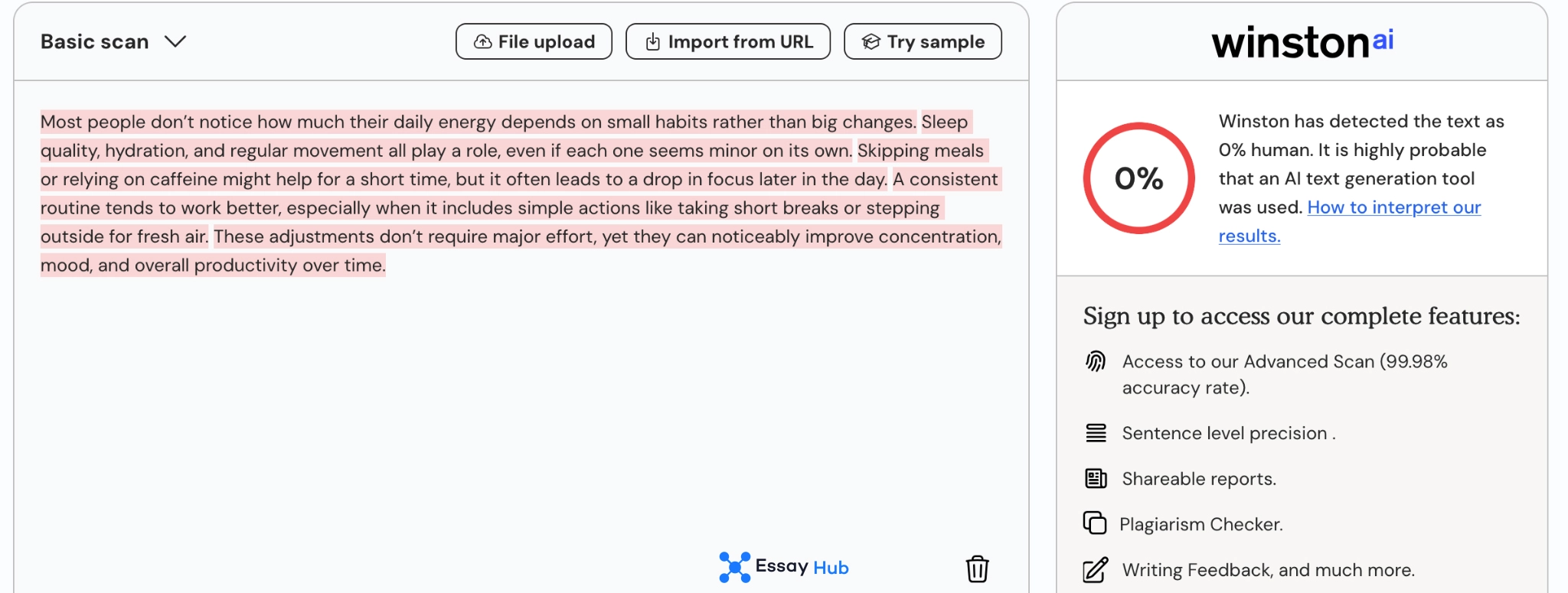
Winston reports a false positive rate of 1.5%, and independent measurements align with that number. This consistency is rare across tools. It suggests stable calibration under the tested conditions. Still, even a 1.5% rate means that errors are expected, not exceptional. At scale, that level of misclassification still produces incorrect flags that require human review.
If you'd rather have a real professional instead of AI models handling your papers, you can also use EssayHub's essay writing service.
Why Technical and ESL Writing is Flagged as AI Writing
Some human writing triggers AI detection even when no AI is involved. The reason sits in structure, not intent. Technical fields rely on standardized terminology, repeated phrasing, and stable sentence patterns. That consistency mirrors what detectors are trained to catch. In one academic dataset, running verified human papers through detectors showed the following numbers:
- 36.9% average AI score under one system
- 27.55% average AI score under another
- Up to 30.4% of human articles flagged as AI by one detector
- 16% flagged by another
Those numbers are too high to ignore.
Language patterns add another layer. Non-native English often follows simpler grammar and more predictable sentence construction. Detection models interpret that predictability as machine-like behavior. The system does not understand context. It measures statistical regularity. Academic writing, especially in STEM, tends to compress variation. That compression lowers unpredictability, which detectors rely on as a signal of human authorship. When variation drops, scores rise. The text remains human, yet the pattern suggests otherwise.
If you need to use AI tools for your research but are worried about their reliability, check out our article on OpenAI Prism privacy.
How Paraphrasing Reduces Detection Accuracy
Paraphrasing changes how detection systems read text. These systems perform best when the AI output stays intact. Once a person edits the draft, the signal weakens measurably. In a controlled study, recall dropped by 20.6%, meaning the system missed more AI-generated content after editing. Accuracy fell by 9.1%, precision by 3.7%, and F1 scores by 12.6%. Those shifts reflect a real decline in detection strength.
The mechanism becomes clearer through similarity metrics. The Jaccard Similarity Index works like a “text DNA test.” It measures how much of the original wording survives. When similarity remains high, detection holds. In lightly edited drafts, Jaccard reached 0.69, and detectors still recognized the pattern. When similarity dropped, detection weakened. In successfully disguised texts, Jaccard fell to 0.501, and cosine similarity to 0.771. That indicates deeper rewriting.
Detection systems rely on statistical resemblance. Paraphrasing disrupts that resemblance. Once the structure shifts enough, the model loses its reference point, and confidence drops accordingly.
Limits of AI Detection Accuracy
There is still no stable baseline that defines what “accurate” means in AI detection. Most research relies on clean comparisons: fully human writing against fully AI generated text. In that setup, performance looks strong. One large dataset recorded 99.58% AI likelihood for GPT-4o output, paired with near-perfect classification at a defined cutoff. Those conditions are controlled. They do not reflect how people actually write.
Real writing is somewhere in between. AI already changed productivity for Gen Z: students often use AI for structure, then rewrite or expand the content themselves. That hybrid process changes the statistical signal detectors rely on. The effect is measurable. In one experiment, manual editing reduced recall by 20.6%, accuracy by 9.1%, and F1 scores by 12.6%. The system did not fail outright, yet its confidence weakened.
What remains missing is reliable data on this middle ground. Current studies rarely isolate hybrid writing as a separate category. Detectors still output scores, but those scores become harder to interpret once authorship is mixed.
AI Detection as a Signal, Not Proof
AI detection works through probability. The system evaluates patterns, then assigns a likelihood that a text was generated by a model. That number is not a fact. It is an estimate shaped by training data and statistical assumptions.
Even under controlled conditions, errors remain. One study reported a 12% overall error rate, including 14% false positives where human writing was flagged, and 5% false negatives where AI content passed undetected. These are not edge cases. They are built into the system.
That is why detection results need context. A high score can raise a question, yet it cannot answer it. Additional evidence becomes necessary. Draft history, writing progression, and direct evaluation all carry more weight than a single percentage. Without that context, the output remains a signal, not a conclusion.

Mark Bradford, a passionate and talented artist, utilizes his innovative spirit to support academic pursuits. In partnering with EssayHub, he leverages his artistic insights to assist students as a professional essay writer, helping them navigate and complete their academic assignments at every level of difficulty.
- Paustian, T., & Slinger, B. (2024). Students are using large language models and AI detectors can often detect their use. Frontiers in Education, 9. https://www.frontiersin.org/journals/education/articles/10.3389/feduc.2024.1374889/full
- Erol, G., Ergen, A., Erol, B. G., Ergen, Ş. K., Bora, T. S., Çölgeçen, A. D., Büşra Araz, Cansel Şahin, Günsu Bostancı, İlayda Kılıç, Zeynep Birce Macit, Umut Tan Sevgi, & Abuzer Güngör. (2025). Can we trust academic AI detective? Accuracy and limitations of AI-output detectors. Acta Neurochirurgica, 167(1). https://link.springer.com/article/10.1007/s00701-025-06622-4
- Hastewire. (2023). Hastewire AI Detector. https://hastewire.com/blog/winston-ai-detector-accuracy-real-user-insights-2023

.webp)

